TPUアーキテクチャ:グーグルの7世代完全ガイド
GoogleのTensor Processing Unitsは、あなたが毎日使っている最先端のAIモデルの大部分を動かしていますが、ほとんどのエンジニアは驚くほどそのアーキテクチャを知らないままです。NVIDIA GPUが開発者のマインドシェアを独占している一方で、TPUはGemini 2.0、Claude、その他何十もの最先端モデルを、従来のGPUインフラを使用するほとんどの組織が倒産するような規模で、静かに訓練し、提供している。Anthropicは最近、将来のClaudeモデルを訓練するために、100万個以上のTPUチップ(1ギガワット以上の計算能力に相当)を導入することを約束した¹ Googleの最新のIronwood世代は、9,216チップのスーパーポッドに42.5エクサフロップスのFP8計算を提供し、プロダクションAIインフラストラクチャの意味を再定義する規模となっている²。
TPUの背後にある技術的な洗練は、単純な性能指標をはるかに超えている。これらのプロセッサは、GPUとは根本的に異なる設計思想を体現しており、汎用的な柔軟性と引き換えに、行列の乗算やテンソル演算に極めて特化している。TPUアーキテクチャを理解するエンジニアは、1サイクルあたり65,536回の乗積演算を処理する256×256のシストリック・アレイを利用したり、組み込み負荷の高いワークロードに第3世代のSparseCoreアクセラレータを活用したり、マルチペタビットのデータセンター・トポロジーを10ナノ秒以下で再構成する光回路スイッチをプログラムしたりすることができます。
この先の技術的な内容は、慎重な注意を要する。7世代にわたるTPUの進化を検証し、シストリックアレイの数学とデータフローパターンを解剖し、SRAMタイルからHBM3eチャネルまでのメモリ階層を探求し、中間表現レベルでのXLAコンパイラ最適化を分析し、集団演算の実行速度が同等のイーサネットベースのGPUクラスタよりも10倍速い理由を調査します。⁴ レジスタレベルの仕様、サイクル精度の高いパフォーマンスモデリング、TPUをGPUよりも強力かつ制約の多いものにするアーキテクチャ上のトレードオフに遭遇するでしょう。ここでは、次世代のAIインフラストラクチャーを構築するエンジニアや、現在のアクセラレーターが達成できることの限界を押し広げる研究者に役立つ情報が満載です。
進化:建築革新の7世代
TPU v1:推論のみに特化(2015年)
Googleは、2015年に最初のTensor Processing Unitを導入し、重大な問題に対処しました。ニューラルネットワークの推論ワークロードは、同社のデータセンターの設置面積を倍増させる恐れがありました。このチップは、256×256シストリック配列の8ビット整数積和演算ユニットを搭載し、わずか28~40ワットの熱設計電力で毎秒92テラオプスを実現した。
このアーキテクチャは、急進的なミニマリズムを体現している。1つの行列乗算ユニットが、ウェイト定常データフローによってINT8演算を処理し、ウェイトはシストリック配列に固定されたまま、アクティブはグリッド上を水平方向に流れる。部分和は垂直方向に伝搬されるため、行列乗算全体の中間メモリ書き込みが不要になる。PCIe経由でホスト・システムに接続されたチップは、外部メモリにDDR3 DRAMを使用し、700MHzで動作した。
パフォーマンスの向上はグーグルのエンジニアをも驚かせた。TPU v1は、本番の推論ワークロードにおいて、現代のCPUやGPUと比較して、ワットあたりの演算処理で30倍から80倍の改善を達成した⁸ このチップは、Google検索ランキング、1日10億件のリクエストを処理する翻訳サービス、20億人のユーザーに対するYouTubeレコメンデーションを処理した。この成功は、狭い作業負荷に最適化された専用アクセラレーターが、汎用プロセッサーよりも桁違いの向上を実現できるという、アーキテクチャの中核的な洞察を実証した。
TPU v2:規模に応じたトレーニングを可能にする(2017年)
第2世代は、TPUを推論のみのアクセラレータから完全なトレーニングプラットフォームへと変貌させた。Googleは、浮動小数点演算を中心にアーキテクチャ全体を再設計し、256×256のINT8アレイをコアごとにデュアル128×128のbfloat16乗算アキュムレータに置き換えた⁹ 各チップには、コアごとに8GBの高帯域幅メモリを共有する2つのTensorCoreが搭載されており、DDR3からの大規模なアップグレードにより、ニューラルネットワークのトレーニングに必要な帯域幅を提供した。
Bfloat16の精度はTPU v2の成功に不可欠であることが証明された。このフォーマットは、FP32と同じ8ビットの指数範囲を維持する一方で、仮数を7ビットに減らし、トレーニングのダイナミックレンジを維持しながら、必要なメモリ帯域幅を半分にする。
TPU v2を真に差別化したアーキテクチャの革新は、チップ間相互接続(ICI)だった。これまでのアクセラレータは、マルチチップ通信にイーサネットやインフィニバンドを必要とし、レイテンシや帯域幅のボトルネックとなっていた。Googleはカスタム高速双方向リンクを設計し、各TPUを2Dトーラスのトポロジーで4つの隣接チップに直接接続した¹¹この相互接続により、最大256チップのTPU v2「ポッド」が1つの論理アクセラレータとして機能し、all-reduceのような集団演算がネットワークベースの代替よりもはるかに高速に実行されるようになった。
TPU v3:水冷パフォーマンス・スケーリング(2018年)
GoogleはTPU v3でクロックスピードとコア数を積極的に押し上げ、1チップあたり420テラフロップスを実現し、v2の2倍以上の性能を達成した¹²。電力密度の向上は、液冷という劇的なアーキテクチャの変更を余儀なくさせた。各TPU v3ポッドは水冷インフラを必要とし、前世代やほとんどのデータセンターアクセラレータの空冷設計とは一線を画した¹³。
このチップは、128×128のデュアルMXUアーキテクチャを維持しつつ、コアの総数を増やし、メモリ帯域幅を改善した。各TPU v3には、それぞれ2つのコアを持つ4つのチップが搭載され、チップ全体で合計32GBのHBMメモリーを共有する。¹⁴ ベクトル処理ユニットは、活性化関数、正規化演算、および行列ユニットだけではトレーニングのボトルネックになることが多かった勾配計算のための機能強化を受けた。
v2と同じ2DトーラスICIトポロジーを使用し、リンクあたりの帯域幅を増加させることで、2,048チップのポッドに展開しました。Googleは、v3ポッドでますます大規模なモデルをトレーニングし、トーラスのトポロジーがネットワーク直径を縮小し(2つのチップ間の最大距離はNではなくN/2としてスケールする)、データ並列およびモデル並列トレーニング戦略の両方で通信オーバーヘッドを最小化することを発見した¹⁵。
TPU v4:光回路スイッチングのブレークスルー(2021年)
第4世代は、初代TPU以来、グーグルにとって最も重要なアーキテクチャーの飛躍だった。エンジニアはポッドのスケールを4096チップまで拡大し、データセンター規模のMLインフラに革命をもたらした電気通信から拝借した技術である光回路スイッチング(OCS)を相互接続に導入した¹⁶。
TPU v4 のコア・アーキテクチャは、強化されたベクトル・ユニットとスカラー・ユニットに加え、TensorCore 1 つにつき 128×128 の MXU を 4 つ備えている。各 TensorCore のペアは、コアごとの Vector Memory に加え、128MB の Common Memory を共有し、より洗練されたデータステージングと再利用パターンを可能にした¹⁷ チップトポロジは 2D から 3D トーラスに進化し、各 TPU を 4 つではなく 6 つの隣接する TPU に接続することで、ネットワーク直径をさらに縮小し、バイセクショ ンのバンド幅を改善した。
光回線交換システムは、大規模展開のすべてを変えた。グーグルは、TPU間の固定配線ではなく、どのチップをどのチップに接続するかを動的に再構成できるプログラマブル光スイッチを導入した。MEMS(微小電気機械システム)ミラーが光ビームを物理的に方向転換し、任意のTPUペアをつなぎ合わせることで、光ファイバー伝送時間以上の待ち時間を実質的にゼロにする。
OCSアーキテクチャは、以前は不可能だった機能を可能にした。グーグルは、光スイッチを適切にプログラミングすることで、4チップから4096チップのポッド全体まで、あらゆるサイズの「スライス」を用意することができた。故障したチップは、ラック全体をダウンさせることなく、シームレスにルーティングすることができる。最も注目すべきは、物理的に離れたデータセンターのTPUをネットワークトポロジー上で論理的に隣接させることができ、物理的レイアウトと論理的レイアウトを完全に切り離すことができたことだ。
TPU v4では、推薦システム、ランキングモデル、膨大な語彙を埋め込む大規模言語モデルで日常的に使用される埋め込み処理を処理するための専用プロセッサ、SparseCoreも導入されました。SparseCoreは、1チップあたり4つの専用プロセッサを搭載し、それぞれが2.5MBのスクラッチパッドメモリと、スパースメモリアクセスパターンに最適化されたデータフローを備えています。
TPU v5pとv5e:専門化と規模拡大(2022-2023年)
Googleは第5世代を、異なるユースケースをターゲットとした2つの異なる製品に分割した。TPU v5pは大規模なトレーニングのために最大限のパフォーマンスを優先し、v5eはコスト効率の良い推論と小規模なトレーニングジョブのために最適化された²¹。
TPU v5pは8,960チップポッドで毎秒約4.45エクサフロップスを達成し、v4の最大ポッドサイズの2倍以上となった²²インターコネクト帯域幅はチップあたり4,800Gbpsに達し、3Dトーラストポロジーは16×20×28の巨大なスーパーポッドでチップを接続した。光回線スイッチング・ファブリックは、v5pスーパーポッド全体の配線を48台のOCSユニットで13,824個の光ポートを管理し、コンピューティング史上最大規模の量産光スイッチング配備を実現しました。
TPU v5eは異なるアプローチを取り、コア数とクロックスピードを減らして、積極的な消費電力とコストの目標を達成した。推論に最適化されたチップには、1チップあたり2つのTPUコアではなく1つのTPUコアしか含まれておらず、2Dトーラストポロジーに戻り、より小さなポッドサイズで十分だった²⁴。アーキテクチャの簡素化により、Googleは、絶対的なパフォーマンスがドルあたりのパフォーマンスよりも重要でないワークロードに対して、v5eを競争力のある価格にすることができた。
TPU v6e トリリウム:マトリックスの性能を4倍に(2024年)
トリリウムは、マトリックス・マルチプライ・ユニットを128×128から256×256のマルチプライ・アキュムレータに拡張することで、アーキテクチャの転換点を示しました。
メモリサブシステムも同様に劇的なアップグレードを受けた。HBMの容量はチップあたり32GBに倍増し、帯域幅は次世代HBMチャネルによって倍増しました。²⁶ チップ間インターコネクトの帯域幅も同様に倍増し、256個のTrilliumチップのポッドが、計算と通信の両方に重点を置いたモデルでより高いスループットを維持できるようになりました。
Trillium は第 3 世代の SparseCore アクセラレータを搭載し、ランキングやレコメンデーション のワークロードにおける超大規模エンベッディングの機能を強化しました。更新された設計では、メモリ・アクセス・パターンが改善され、行列の乗算ではなくエンベッディングのルックアップが主なモデルのために、SparseCoreとHBM間の適切なバンド幅が増加しました。
グーグルは、高度なプロセス・ノード、無駄な作業を削減するアーキテクチャの最適化、およびチップのすべての部分に同時にストレスを与えないようなオペレーション時に未使用のユニットを注意深くパワー・ゲーティングすることにより、効率の向上を達成しました。
TPU v7 アイアンウッドFP8の時代(2025年)
Googleの第7世代TPU(コードネーム:Ironwood)は、ネイティブのFP8をサポートし、最先端のトレーニング性能を維持しながら「推論の時代」専用に最適化された初のTPUです。
メモリシステムは、1チップあたり192GBのHBM3eメモリに拡張され、これはTrilliumの容量の6倍に相当し、帯域幅は7.4TB/秒に達しました。Googleは、新たに登場するマルチモーダルモデルや、100万トークンウィンドウに迫るロングコンテキストのアプリケーションをサポートするために、メモリ容量を特別に設計しました。
Ironwoodのインターコネクトは、4つのICIリンクを通じて9.6Tbpsの双方向総帯域幅を提供し、チップあたりのピーク帯域幅は1.2TB/秒になる。³³アーキテクチャは、小規模展開用の256チップポッドから、42.5FP8エクサフロップスのコンピュートパワーを提供する。³⁴ GoogleのJupiterデータセンター・ネットワーク・テクノロジーは、理論的には1つのクラスターで最大43個のIronwoodスーパーポッドをサポートできる。
FP8のサポートは、精度戦略の根本的な転換を意味する。以前のTPU世代では、ソフトウェア技術を使って8ビット演算をエミュレートしていたため、オーバーヘッドが発生していた。Ironwoodは、E4M3(指数4ビット、仮数3ビット)とE5M2(指数5ビット、仮数2ビット)の両方のフォーマットをサポートするネイティブのFP8乗積算ユニットを実装しています。
Anthropic社は、2026年から100万個以上のIronwoodチップを導入することを約束しており、このアーキテクチャの生産準備が整っていることを示している。同社は、1ギガワットをはるかに超えるTPU容量(小さな都市に電力を供給するのに十分な容量)を、Claudeモデルのトレーニングとサービス専用に活用する計画だ。
現行世代クイック・リファレンス
以下の表は、2025年の生産展開に最も関連性の高い3つの現世代TPUについて、読み取れる仕様を示している:
表1:コア・コンピュート仕様

仕様TPU v5eTPU v5pTPU v6e(トリリウム)TPU v7(アイアンウッド)
MXU アレイサイズ 128×128 128×128 256×256 256×256
サイクルあたりのMAC数 16,384 16,384 65,536 65,536
ピークBF16 TFLOPS ~197 ~459 ~918 ~2,300 (推定)
ピーク FP8 PFLOPS N/A(エミュレーテッド) N/A(エミュレーテッド) N/A(エミュレーテッド) 4.6
ネイティブ精度 BF16、INT8 BF16、INT8 BF16、INT8 BF16、FP8、INT8
テンソルコア/チップ 1 2 1 1
表2:メモリと帯域幅

仕様TPU v5eTPU v5pTPU v6e(トリリウム)TPU v7(アイアンウッド)
HBM 容量 16 GB 95 GB 32 GB 192 GB
HBM世代 HBM2e HBM2e HBM HBM3e
メモリ帯域幅 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s
バイト/FLOP比 ~4.2 ~6.0 ~1.7 ~3.2
表3:相互接続とスケーリング
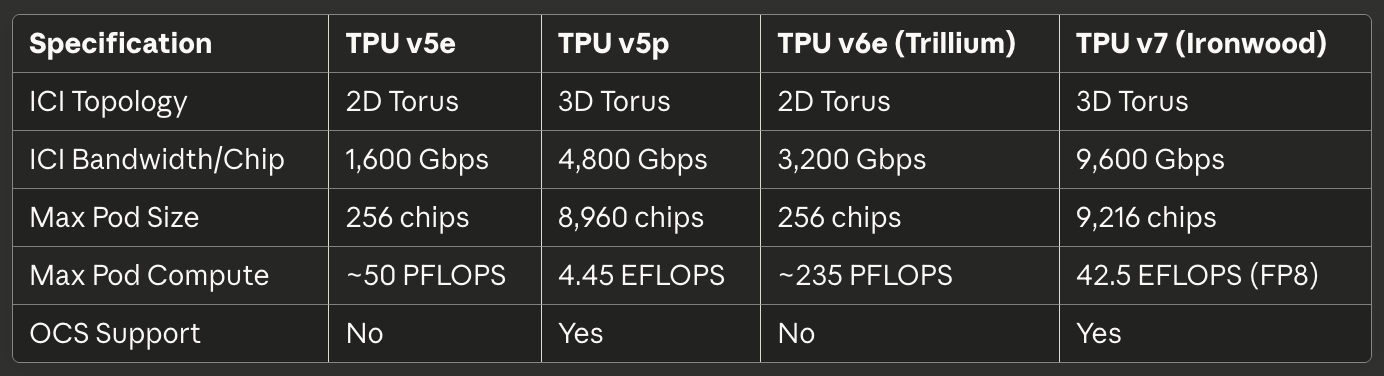
仕様TPU v5eTPU v5pTPU v6e(トリリウム)TPU v7(アイアンウッド)
ICIトポロジー 2D トーラス 3D トーラス 2D トーラス 3D トーラス
ICI 帯域幅/チップ 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps
最大ポッドサイズ 256チップ 8,960チップ 256チップ 9,216チップ
最大ポッド演算 ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8)
OCSサポート なし なし なし
表4:パワーと効率

仕様TPU v5eTPU v5pTPU v6e(トリリウム)TPU v7(アイアンウッド)
TDP ~120-200W ~250-300W ~120-200W 600W
冷却空気 液体 空気 液体
TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8
エネルギー vs 先行世代ベースライン N/A v5eより67%向上 トリリウムより2倍向上
表5:推奨ユースケース

ユースケース ベストチョイス
コスト最適化された推論 TPU v5e:推論クエリーあたりの最安コスト
大規模トレーニング(>1000チップ) TPU v5pまたはIronwood 3Dトーラス + OCSで大規模ポッドを実現
ミディアムトレーニングジョブ(256チップ) TPU v6e Trillium 最高のパフォーマンス/ワット、v5eと比較して4.7倍の計算能力
メモリバウンドモデル(>70Bパラメータ)、Ironwood 192GB HBMは、より大きなバッチサイズを可能にします。
ロングコンテキストの推論(>100Kトークン) アイアンウッドHBMの容量が大容量KVキャッシュをサポート
組み込み負荷の高いワークロード TPU v5pまたはIronwood SparseCore + 大容量HBM
ハードウェア・アーキテクチャシリコン内部
シストリック・アレイの数学とデータフロー
シストリックアレイを理解するには、GPU SIMDレーンとは根本的に異なる並列化へのアプローチを把握する必要がある。シストリックアレイは、乗算積算ユニットをグリッド状に連鎖させ、データが構造中をリズミカルに流れるようにします。
TPU v6eの256×256のシストリック・アレイが行列乗算C=A×Bを実行することを考える。エンジニアは行列Bの重みを、グリッド状に配置された65,536個の個々の乗算積算ユニットにあらかじめロードしておく。行列Aの活性化値は左端から入り、アレイを水平方向に流れる。各MACユニットは、保存されている重みを入力された活性化値と掛け合わせ、その結果を上から届く部分和に加え、活性化値(水平方向)と更新された部分和(垂直方向)の両方を隣のユニットに渡す。
データフローパターンは、各活性化値が水平次元を横断する際に256回再利用されることを意味し、各部分和は垂直方向に流れる際に256回の乗算による寄与を蓄積する。重要なのは、すべての中間結果は、メモリへのラウンドトリップではなく、短いワイヤーを介して隣接するMACユニット間を直接通過することである。このアーキテクチャは、毎クロック・サイクルで65,536回の乗算累積演算を実行し、数百万回の演算を含む可能性のある行列乗算全体において、DRAMやオンチップSRAMに触れる中間値はゼロである。
weight-stationaryデータフローパターンは、ニューラルネットワークの推論やトレーニングで最も一般的なケースである、多くの異なる活性化行列に同じweight行列を繰り返し乗算する場合に最適化される。エンジニアはウェイトを一度ロードし、その後、再ロードすることなく配列を通して無制限の活性化バッチをストリーミングする。このパターンは、畳み込み層、完全連結層、トランスフォーマーモデルを支配するQ-K^Tとattention-V演算に非常に効果的である。
エネルギー効率は、データの再利用と空間的局所性に起因する。DRAMからの値の読み出しは、1回の乗積演算の約200倍のエネルギーを消費する。⁴² 各重みを256回、各アクティベーションをメモリアクセスなしで256回再利用することで、シストリックアレイは、コンピュートユニットとメモリ階層間でデータを行き来させるアーキテクチャでは不可能なワットあたりの演算比率を達成している。
シストリックアレイの弱点は、動的または不規則な計算パターンで現れます。データは固定スケジュールでグリッドを流れるため、このアーキテクチャは条件付き実行、スパース行列(SparseCoreを使用しない限り)、ランダムなアクセスパターンを必要とする演算に苦戦します。この柔軟性の低さは、一般性と引き換えに、予測可能なアクセスパターンを持つ高密度行列の乗算という、目標とするワークロードの効率を極限まで高めています。
TensorCoreの内部アーキテクチャ
TensorCoreは、ソフトウェアがターゲットとする基本的なビルディングブロックであり、3つのコンポーネント間の相互作用を理解することで、TPUの性能特性とプログラミングパターンの両方が説明できます。
行列乗算ユニットは、FP32 アキュムレーションを使用して、bfloat16 または FP8 入力で 1 サイクルあたり 16,000 回の乗算アキュムレート演算を実行します。⁴ 混合精度アプローチは、アキュムレータの数値精度を維持しながら、入力のメモリ帯域幅を削減します。エンジニアは、アキュムレーション中にFP32の精度を完全に維持することで、数百または数千の中間生成物を合計する際の壊滅的なキャンセル・エラーを防ぐことができる一方、精度を下げた入力が最終的なモデルの品質に影響することはほとんどないことを確認しています。
ベクトル処理ユニットは、MXUの硬直した構造には不向きな演算を処理する。活性化関数(ReLU、GELU、SiLU)、正規化レイヤ(バッチノルム、レイヤノルム)、ソフトマックス、プーリング、ドロップアウト、および要素ごとの演算は、VPUの128レーンSIMDアーキテクチャで実行されます。 ⁴ ⁵ VPUはFP32およびINT32データ型で動作し、指数や除算が大きなダイナミックレンジを生み出す可能性があるソフトマックスのような数値に敏感な演算に必要な精度を提供します。
スカラーユニットはTensorCore全体をオーケストレーションします。このシングルスレッド・プロセッサは、制御フローを実行し、複雑なインデキシングパターンのメモリアドレスを計算し、高帯域幅メモリからベクターメモリへのDMA転送を開始します。⁴⁶ スカラユニットはシングルスレッドで実行されるため、各TensorCoreは1サイクルあたり1つのDMAリクエストしか作成できません。
TensorCoreに供給されるメモリ階層は、生の計算能力と同様に、達成可能なパフォーマンスを決定する。ベクターメモリ(VMEM)は、各TensorCore専用のソフトウェア管理スクラッチパッドSRAMとして機能し、通常は数十メガバイトのサイズです。XLAコンパイラは、HBMとVMEM間のデータ移動を明示的にスケジュールし、何を高速ローカルメモリにステージングし、いつ結果を書き戻すかを決定します。
TPU v4以降の世代に存在するコモンメモリ(CMEM)は、チップ上のすべてのTensorCoreがアクセス可能な、より大きな共有プールを提供する。TPU v4アーキテクチャでは、2つのTensorCore間で共有される128MBのCMEMが割り当てられ、1つのコアの出力がHBMにラウンドトリップすることなく別のコアの入力に供給される、より洗練されたProducer-Consumerパターンが可能になった。
プログラミングモデルの意味は非常に重要だ。スカラーユニットのシングルスレッドとベクターメモリは明示的な管理を必要とするため、TPUプログラミングは現代のGPUプログラミングというより、1990年代の組み込みシステム開発に似ている。CUDAは、ユニファイドメモリとハードウェア管理キャッシュでメモリ移動を抽象化します。TPUコードは(XLAで生成されたものであれ、Pallasで手書きされたものであれ)、すべてのデータ転送を明示的にオーケストレーションしなければなりません。手動制御は、専門家による最適化を可能にしますが、有能なパフォーマンスに対するハードルを高くします。
高帯域幅メモリー・アーキテクチャ
最新のTPUはHBM(High Bandwidth Memory)、つまりHBM3eを使用しており、CPUで見られるDDR SDRAMや多くのGPUで使用されているGDDRとは根本的に異なるメモリ技術だ。HBMは、シリコン貫通ビア(TSV)を使用して複数のDRAMダイを垂直にスタックし、そのスタックをシリコンインターポーザー上のプロセッサ・ダイに直接隣接させます⁹ 短い電気経路と広いインターフェイスにより、従来のメモリ技術よりも劇的に高い帯域幅を実現します。
TPU v7 Ironwoodは192GBのHBM3eを実装しており、総帯域幅は7.4TB/sです⁰⁰ メモリシステムは複数のチャネルに分割され、それぞれが総容量の別々の部分に独立したアクセスを提供します。XLAコンパイラとランタイムは、並列アクセスを最大化し、1つのチャネルが飽和して他のチャネルがアイドル状態になるホットスポットを回避するために、HBMチャネル間でテンソルを慎重に分割する必要があります。
メモリ・インターフェースの幅は、従来の DRAM を凌駕しています。DDR5 チャネルが 64 ビットの幅を提供するのに対し、HBM チャネルは通常 1,024 ビットに及びます⁵¹ この極端な幅により、比較的控えめなクロック速度で高帯域幅を実現し、狭いインターフェイスを数ギガヘルツの周波数に押し上げるのに比べ、消費電力とシグナルインテグリティの課題を軽減します。
レイテンシ特性はGPUのメモリシステムとは大きく異なる。TPUには、小さなローカルバッファ以上のハードウェア管理キャッシュがないため、アーキテクチャは、コンピュートユニットがデータを必要とするかなり前に、ソフトウェアが明示的にVMEMにデータをステージングすることに依存している。キャッシュがないということは、コンパイラがプリフェッチやダブルバッファリングによってレイテンシをうまく隠さない限り、メモリのレイテンシが性能に直接影響することを意味します。
メモリ容量の限界は、計算スループットよりも多くのワークロードを支配しています。bfloat16の重みを持つ1,750億パラメータのモデルは、パラメータを格納するために350GBを必要とします。これは、アクティブ化、オプティマイザの状態、または勾配バッファを考慮する前であっても、すでにアイアンウッドの192GB HBMを超えています。このようなモデルのトレーニングには、勾配チェックポイント、複数のチップにまたがるオプティマイザ状態のシャーディング、メモリフットプリントを最小化するためのパラメータ更新の慎重なスケジューリングなどの高度な技術が必要です。
TPUランタイムは、MXUの効率を最大化するために、特定のテンソルレイアウト要件を強制する。シストリックアレイは128×8のタイルでデータを処理するため、テンソルはパディングの無駄を避けるためにこれらの寸法に合わせる必要があります。コンパイラはテンソルのパディングと再形成を自動的に試みますが、モデル・アーキテクチャで意識的にレイアウトを選択することで、性能を大幅に向上させることができます。
スパースコアエンベッディング・アクセラレーション
行列乗算ユニットは高密度の行列演算を得意とするが、エンベッディングを多用するワークロードは根本的に異なる特性を示す。レコメンデーションモデル、ランキングシステム、大規模な言語モデルは、不規則でデータに依存するインデックスを通じて、巨大なエンベッディングテーブル(通常は数百ギガバイト)に頻繁にアクセスします。MXUの構造化されたデータフローは、このようなスパースメモリアクセスパターンに対して何の利点ももたらさないため、SparseCoreの特殊なアーキテクチャの動機付けとなっています。
SparseCoreは、MXUのシストリックアレイとは根本的に異なるタイル型データフロープロセッサを実装しています。TPU v4では、1チップに4つのSparseCoreが搭載され、それぞれに16の計算タイルが搭載されています⁵⁶ 各タイルは、ローカルスクラッチパッドメモリ(SPMEM)と処理エレメントを持つ独立したデータフローユニットとして動作します。タイルは並列に実行され、エンベッディングオペレーションのサブセットを同時に処理します。
このメモリ階層では、ホットデータを小型で高速な SPMEM に配置する一方で、完全なエンベッディングテーブルは HBM に保持します。XLA コンパイラーは、エンベッディングアクセスパターンを分析し、どのエンベッディングベクターが SPMEM にキャッシュするメリットがあるのか、HBM からオンデマンドでフェッチするメリットがあるのかを判断します。
スパースコアはHBMチャネルに直接接続し、TensorCoreのメモリパスを完全にバイパスします。この専用接続により、エンベッディング演算が密な行列演算とメモリ帯域幅で競合することがなくなり、両者を並列に進めることが可能になります⁵⁸ このパーティショニングは、密なニューラルネットワーク層と大規模なエンベッディング・ルックアップをインターリーブするディープラーニング推奨モデル(DLRM)のようなモデルで非常にうまく機能します。
mod-shardingストラテジーは、target_sc_id = col_id % num_total_sparse_cores.⁵⁹シンプルなシャーディング関数は、エンベッディングIDが一様に分布している場合の負荷分散を保証しますが、歪んだアクセスパターンのホットスポットを作成する可能性があります。実際のデータを扱うエンジニアは、エンベッディングの頻度分布を分析し、ボトルネックを避けるために手動でシャーディングのバランスを調整する必要があります。
SparseCoreによる性能向上は、MXUやVPUで同じ演算を実装した場合と比べて5~7倍に達します。TPUがGPUの汎用設計を超えて特化しているように、SparseCoresはTPUの行列指向設計を超えて特化しています。
Trilliumの第3世代SparseCoreは、可変SIMD幅(FP32は8要素、bfloat16は16要素)を導入し、メモリアクセスパターンを改善することで、ミスアラインメントリードによる無駄な帯域幅を削減しました。
相互接続技術:スーパーコンピュータの配線
チップ間相互接続(ICI)アーキテクチャ
インターチップ・インターコネクトは、TPUを孤立したアクセラレータとしてではなく、統合されたスーパーコンピュータとして機能させるための重要な技術です。イーサネットやInfiniBandネットワークを介して通信するGPUとは異なり、ICIは隣接するTPUをマイクロ秒単位のレイテンシとテラビット/秒の帯域幅で直接接続するカスタム高速シリアルリンクを実装しています⁶²。
TPU世代間のトポロジーの進化は、ポッドスケーリングの要件の変化を反映している。TPU v2、v3、v5e、v6eは、各チップが最も近い4つの隣接チップ(東西南北)に接続する2Dトーラスのトポロジーを実装しています⁶³リンクは境界で折り返し、接続数の少ないエッジチップを排除したドーナツ型の論理トポロジーを作ります。このように、16×16グリッドの256個のTPUは、どの2つのチップが通信しても、均一な帯域幅とレイテンシ特性を提供します。
TPU v4とv5pは、各チップが6つの隣接チップに接続する3Dトーラストポロジーにアップグレードしました。⁴次元が追加されたことで、ネットワークの直径(2つのチップ間の最大ホップ数)がおよそ2√Nから3ȡNに減少しました。4,096チップのポッドでは、最大ホップ数は約128から48に減少し、all-reduceのようなグローバルに同期する操作のワーストケースの通信レイテンシが大幅に短縮されます。
トロイダル構造は、ワークロードがチップ間でどのように分割されるかに関係なく、等しいバイセクショ ン帯域幅というもう一つの重要な利点を提供します。トーラスを半分に分割するどのカットも同じ数のリンクを横切るので、ジョブの配置が悪くてネットワークのボトルネックになるような病的なケースを防ぐことができます⁵ 一様な二分割帯域幅はスケジューリングを単純化し、後述する光回路スイッチの再構成を可能にします。
帯域幅の仕様は、世代間で驚くほどスケールアップします。TPU v6eは、チップあたり13 TB/sのICI帯域幅を提供します。⁶⁶ TPU v5pは、6つの3Dトーラスリンクでチップあたり4,800 Gbpsに達します。6Tbpsの総双方向帯域幅で、チップあたり1.2TB/秒になります。 ⁸ 比較のために、トップクラスの400GbEネットワークインターフェイスは50GB/秒の双方向帯域幅を提供します。
ラック内のリンク技術では、同じ 4×4×4 のキューブ内のチップ間の短い距離には、直接接続の銅線 (DAC) ケーブルを使います。キューブ間やポッドスケールのリンクは光トランシーバに移行し、より高いコストと電力を、データセンターのラック間に必要な距離と帯域幅と引き換えにします。
集団演算はICIのユニークな特性を利用する。All-reduce、All-gather、Reduce-Scatterの各操作は、トレーニング中にチップ間でアクティブとグラジエントを頻繁に同期させます。イーサネットベースのGPUクラスタでは、これらの集団演算はスイッチ、ケーブル、ネットワークインターフェースカードを備えた階層ネットワークを横断するため、各ホップで待ち時間が発生します。TPU ICIは、最適化された集団アルゴリズムをハードウェアに直接実装し、イーサネットベースのGPU実装と比較して10倍高速に全減少演算を実行します。
光回線交換:ダイナミックなトポロジー再構成
GoogleがTPU v4で光回線スイッチング(OCS)を導入したことは、データセンター・ネットワーキングにおけるここ数十年で最も重要なイノベーションのひとつだ。従来のパケット交換ネットワークは、イーサネットであれInfiniBandであれ、パケットをホップ・バイ・ホップでルーティングすることで論理的な接続を確立する。OCSはその代わりに、プログラマブルな光素子を使用してエンドポイント間に直接物理的な光路を形成し、スイッチングの待ち時間を完全に排除します。
コア技術は、物理的に回転して光ビームを方向転換させるMEMS(微小電気機械システム)ミラーに依存している。TPU A上の送信機がOCSに光を送る。OCS内部の小さなミラーが回転し、その光ビームをTPU B上のレシーバーに反射する。この接続はAからBへの直接的な光パスとなり、ファイバー内を光が伝搬する以上の待ち時間は実質的にゼロである。
再構成速度は、本番システムにおけるOCSの実用性を左右する。グーグルのデプロイメントでは、一般的なネットワーク・プロトコルのラウンドトリップ時間よりも速い、10ナノ秒以下のスイッチング時間を達成しています。³再構成速度は、実行中のジョブを中断させたり、慎重に調整されたトラフィック・エンジニアリングを必要としたりすることなく、ワークロードの要件に合わせた動的なトポロジ変更を可能にします。
TPU v5pは大規模なOCSを実証した。このアーキテクチャは、スイッチングファブリック全体で毎秒4ペタビットの総帯域幅を提供する光回線スイッチを使用しています。 ⁷⁴ 1つのv5pスーパーポッドには、16×20×28の3Dトーラス構成で8,960個のチップを配線するために、13,824個の光ポートを管理する48個のOCSユニットが必要です。
OCSは従来のネットワークでは不可能だった機能を提供する。物理トポロジーと論理トポロジーは完全に切り離され、OCSが直接光パスを作成すれば、データセンターの対角にある2つのTPUが隣接した隣人として見える。故障したチップやリンクは、故障したコンポーネントを除外し、論理的なトーラス構造を維持するために、ミラーを再プログラミングすることでルーティングされます。OCSが適切なポッドコンフィギュレーションを作成するようにプログラムすることで、物理的にラックのケーブル配線を変更することなく、新しいジョブはあらゆるサイズの「スライス」を受け取ることができます。
このアーキテクチャはGoogleのJupiterデータセンターネットワークと統合され、単一のポッドを超えて拡張することができます。Jupiterは、Googleのカスタムシリコンスイッチとコントロールプレーンを使って、データセンター全体にマルチペタビット/秒のバイセクション帯域幅を提供する。
消費電力と信頼性の特性から、TPU規模の展開には光回線交換が有利である。従来のパケットスイッチは、テラビット毎秒のレートでパケットを処理し転送するために、かなりの電力を消費していた。OCS スイッチは、リコンフィギュレーション時に MEMS ミラーを動作させるためだけに電力を消費し、その後はアイド ル状態になり、接続が安定したまま最小限の損失で光を通過させる。
ポッドアーキテクチャとスケーリング特性
TPUポッドは、ICIを通じて接続されたTPUの最大の単一単位を表し、統一されたアクセラレータを形成する。物理的な構造は、個々のチップから、トレイ、キューブ、ラック、完全なポッドへと階層的に構築される⁸⁰ 階層構造を理解することは、異なるスケールでのメモリ容量、通信帯域幅、耐障害性を推論する上で重要である。
基本的なビルディングブロックは、PCIeを介してホストCPUに接続された1つのトレイ上の4つのチップで構成される。PCIe接続は、制御プレーン操作、初期プログラムのロード、トレーニングデータと推論結果のインフィード/アウトフィードを処理する。分散トレーニングのための実際のチップ間通信は、PCIeではなくICIを介して行われるため、PCIeの帯域幅のボトルネックを回避できる。
16個のトレイ(64チップ)が、ポッド構築の基本単位である1つの4×4×4キューブを形成します。キューブ内では、すべてのICI接続に直接接続された銅線ケーブルが使用され、チップは物理的な距離が短い同じラックに配置されます。 ⁸ キューブは、ラップアラウンド接続で完全な3Dトーラスを実装し、理論的には独立して動作する自己完結型の64チップユニットを作成します。
TPU v4ポッドは、合計4,096個のチップを搭載する64個のキューブに拡張可能です。OCSは、これらの4096個のチップを単一の巨大なポッド、複数の小さな独立したポッドとしてプロビジョニングすることができます。この柔軟性により、データセンターのオペレータは、さまざまなジョブサイズと優先順位にわたって利用率のバランスをとることができます。
TPU v5pはポッドのスケールを16×20×28の3Dトーラスの8,960チップに押し上げた!このポッドは4.45エクサフロップスの演算を実現し、実運用で展開されているシングルポッド構成としては最大級のものです。
9,216チップの構成は、42.5 FP8 exaflopsを実現し、わずか5年前のスーパーコンピュータTop500の全リストを上回る計算能力を提供します。
スケーリング効率は、より大きなポッドが実際に役立つかどうかを決定する。ポッドサイズが大きくなると、チップは計算よりも同期に多くの時間を費やすため、通信オーバーヘッドが増加する。Google Researchは、特定のワークロードに対して、32,768 TPUで95%のスケーリング効率を実証した結果を発表しました。これは、32,768 TPUが、完全な線形スケーリングが予測する性能の95%を実現したことを意味します。
ポッドスケールでのフォールト・トレランスには、洗練された取り扱いが必要である。何千ものチップが連続稼動するシステムでは、統計的確率によってコンポーネントの故障が保証される。光回線スイッチは、故障したコンポーネントの周囲で再構成することにより、グレースフルな劣化を可能にする。トレーニングのチェックポイントは一定間隔(通常は数分ごと)で行われるため、ジョブが失敗した場合は、ゼロからではなく、最後のチェックポイントから再開する必要がある。
ソフトウェア・スタックコンパイラ、フレームワーク、プログラミングモデル
XLAコンパイラ:計算グラフの最適化
XLA (Accelerated Linear Algebra)は、TPUのソフトウェアスタックの基礎を形成し、高レベルフレームワーク操作をTPU上で実行するために最適化されたマシンコードにコンパイルする⁸⁹ このコンパイラは、機械学習ワークロードとTPUアーキテクチャ特性に関するドメイン知識を利用するため、汎用コンパイラでは不可能な積極的な最適化を実装している。
FusionはXLAで最もインパクトのある最適化である。コンパイラは計算グラフを解析し、中間テンソルを実体化することなく実行できる演算シーケンスを特定する。単純な例として、relu(batch_norm(conv(x)))のような要素ごとの演算は、通常、畳み込み出力をメモリに書き込み、それを読み出してバッチ正規化を行い、その結果をメモリに書き込み、再び読み出してReLUを行う必要がある。XLAでは、これらの操作を単一のカーネルに統合し、中間的なメモリトラフィックなしに最終的なReLU出力を生成する。
Fusionのインパクトは、TPUのアーキテクチャによってスケールする。MXUは、メモリシステムがデータを供給できるよりも速く行列の乗算を実行できます。MXUは、メモリシステムがデータを供給できるよりも速く行列の乗算を実行できます。Fusionによって中間メモリの書き込みと読み込みを排除することは、性能向上に直結し、活性化関数を多用するネットワークでは2倍以上の高速化を実現することがよくあります。
メモリレイアウトの変換は、ハードウェア要件に合わせてテンソルストレージを最適化する。ニューラルネットワークは、直感的なインデックス作成のために、テンソルをNHWC形式(バッチ、高さ、幅、チャンネル)で表現することがよくありますが、TPU MXUは、128×8タイルに整列したレイアウトで最高のパフォーマンスを発揮します。
コンパイラは、洗練された定数の折りたたみとデッドコードの除去を実装している。MLグラフには、出力が定数のみに依存する部分グラフ(バッチ正規化パ ラメータ、推論の脱落率、バッチ毎ではなく一度だけ実行される形状計算など) が頻繁に含まれます。XLAは、これらの部分グラフをコンパイル時に評価し、定数テンソルに置き換えることで、実行時の作業を削減します。
クロスレプリカ最適化は分散実行に関する知識を利用する。複数のTPUコアにまたがってトレーニングする場合、特定の操作(バッチ正規化統計のような)は、すべてのレプリカにまたがって集約する必要があります。XLAはこれらのパターンを識別し、明示的なメッセージパッシングによって集約を実装するのではなく、ICIのハードウェアアクセラレーションによるall-reduceを利用した最適化された集団演算を生成する。
コンパイラは、TPUに特化した中間表現Mosaicをターゲットにしている。Mosaicはアセンブリ言語よりも高い抽象度で動作するが、入力計算グラフよりも低い抽象度である。この言語は、シストリック・アレイ、ベクトル・メモリ、VMEMステージングなどのTPUアーキテクチャの特徴を公開する一方で、命令スケジューリングやレジスタ割り当てなどの低レベルの詳細は隠します。
オートチューニング機能は、経験的な探索を通じて最適なタイルサイズと動作パラメータを選択します。XLAオートチューニング(XTAT)システムは、様々なフュージョン戦略、メモリレイアウト、タイルサイズを試し、各バリアントのパフォーマンスをプロファイリングし、最も高速な構成を選択します。
JAX:コンポーザブル変換とSPMD
JAXは、自動微分、XLAへのJITコンパイル、プログラム変換のファーストクラスのサポートを備えた数値計算のためのNumPy互換インターフェースを提供する。
JAXの抽象化の中核は、関数に数学的変換を適用することである。Grad (f) fの勾配を計算する。vmap(f) はfを新しい次元にベクトル化します。jit(grad(vmap(f)))は、ベクトル化された勾配関数をコンパイルします。 ⁹⁸ 構成モデルは、単純でテスト可能なコンポーネントから複雑な分散学習ループを構築することができます。
SPMD(Single Program, Multiple Data)はJAXの分散実行モデルを表している。プログラマは、あたかも単一のデバイスをターゲットにしているかのようにコードを書き、次に複数のTPUコアにまたがってテンソルを分割する方法を示すシャーディングアノテーションを追加する。XLAコンパイラとGSPMD(General SPMD)サブシステムは、分散デバイス間で実行されている間、プログラムのセマンティクスを維持するための通信操作を自動的に挿入します。
Shardingアノテーションは、PartitionSpecを使用して分散戦略を宣言します。PartitionSpec('batch', None)は、テンソルの最初の次元をデバイスメッシュの'batch'軸で分割し、2番目の次元を複製します。PartitionSpec(None, 'model')は、2番目の次元を分割することによってテンソルの並列性を実装します。アノテーションは任意のテンソルのランクとデバイスメッシュの次元で構成することができます。
GSPMDの自動並列化により、膨大な量の定型コードが不要になります。従来の分散トレーニングでは、完全なテンソルを必要とする操作の前にall-gatherを、分散勾配を計算した後にreduce-scatterを、グローバルな削減のためにall-reduceを手動で挿入する必要がありました。GSPMDはシャーディングの仕様を分析し、自動的に適切なコレクティブを挿入するため、プログラマは通信エンジニアリングではなくアルゴリズムに集中することができます。
コンパイラは、制約解決を使用して、計算グラフを通してシャーディングの決定を伝播する。演算Aが演算Bによって消費されるシャーディングされたテンソルを出力する場合、GSPMDは出力がどのように使用されるかに基づいてBの最適なシャーディングを推論し、数学的に必要な場合にのみ再シャーディング演算を挿入する可能性がある。
with_sharding_constraintは、自動推論をオーバーライドして、グラフの位置に特定のシャーディングを強制します。カスタムPJIT(並列JIT)アノテーションは、パフォーマンスが重要なコード・パスに対して、正確なデバイス配置とシャーディング戦略を指定します。レイヤーモデルは、自動シャーディングによる迅速なプロトタイピングを可能にすると同時に、必要に応じて専門家による最適化をサポートします。
Shardyは2025年にGSPMDの後継として登場し、改良された制約伝播アルゴリズムと動的形状のより良い取り扱いを実装している。
PyTorch/XLA:TPUにPyTorchを持ち込む
PyTorch/XLAは、PyTorchの命令型プログラミングモデルとXLAのグラフベースコンパイルのギャップを埋めることで、最小限のコード変更でTPU上でPyTorchモデルを実行することを可能にします。
根本的な課題は、PyTorchの熱心な実行哲学に起因しています。PyTorchはPython文が実行されると即座に処理を実行するため、標準的なツールでデバッグができ、制御フローも自然です。XLAではコンパイル前に完全な計算グラフをキャプチャする必要があり、イーガー実行とグラフコンパイルのパフォーマンスの利点の間に緊張が生じます。
PyTorch/XLA 2.4では、インピーダンスのミスマッチに対処するために、eagerモードのサポートを導入しました。この実装は動的にPyTorchの操作をXLAのグラフにトレースし、開発者はXLAのコンパイルの恩恵を受けながら標準的なPyTorchのコードを書くことができます。
グラフ・モードは、本番環境でのデプロイメントのための主要なパスです。開発者は、デコレーターやコンパイルAPIを使用して、XLAコンパイル用の関数を明示的にマークする。明示的なアノテーションは積極的な最適化を可能にするが、どの操作を単一のXLAグラフに融合させるべきか、独立して実行させるべきかを理解する必要がある。
Pallasの統合により、カスタムカーネル開発がPyTorch/XLAにもたらされます。Pallas は、XLA の自動フュージョンが不十分であったり、特殊な処理で手作業による最適化が必要な場合に、TPU カーネルを記述するための低レベル言語を提供します⁹⁹ 言語は、生のアセンブリよりも高レベルのまま、TPU メモリ階層 (VMEM、CMEM、HBM) と計算ユニット (MXU、VPU) を公開します。
内蔵のPallasカーネルは、FlashAttentionやPagedAttentionのようなパフォーマンスが重要な処理を実装します。FlashAttentionのタイル型アテンション計算は、シーケンス長nに対して必要なメモリ帯域幅をO(n²)からO(n)に削減し、固定メモリ予算内でより長いシーケンスを処理することを可能にします。
PyTorch/XLA ブリッジは、当初 GPU 向けに設計された高性能サービングフレームワークである vLLM TPU にとって非常に重要であることが証明された。この実装では、PyTorchフロントエンドの互換性を維持しながら、JAXの優れた並列性サポートを利用し、PyTorchモデルでもJAXを中間低速パスとして使用しています。
改善されたにもかかわらず、モデルの互換性の問題が残っている。PyTorchの操作の中にはXLAに相当するものがなく、パフォーマンスを低下させるCPU実行へのフォールバックを余儀なくされるものがある。動的な制御フローはグラフコンパイルではうまくサポートされず、動的な振る舞いを静的でコンパイル可能な代替に置き換えるためにアーキテクチャの変更が必要になることがよくあります。PyTorch/XLA リポジトリは互換性を文書化し、よくある問題のあるパターンの移行ガイドを提供します。
精度フォーマット:BFloat16、FP8、量子化
TPUの低精度算術演算のサポートにより、許容可能なモデル品質を維持しながら、パフォーマンスとメモリを劇的に向上させることができます。最適なパフォーマンスを達成するためには、さまざまなフォーマットの数値特性とそれぞれの適用タイミングを理解することが重要です。
BFloat16は、TPU v2で初めて登場した、Googleの低精度トレーニングに対する初期の賭けである。 このフォーマットは、FP32の8ビットの指数を維持する一方で、仮数を7ビット(プラス符号ビット)に切り捨てる¹¹⁵ 指数範囲を完全にすることで、勾配がFP16の表現可能な範囲を頻繁に逸脱する、初期のFP16トレーニングで悩まされていたアンダーフローやオーバーフローを防ぐ。
仮数を減らすと量子化誤差が生じるが、最終的なモデル品質に影響を与えることはほとんどない。エンジニアの観察によると、bfloat16でトレーニングされたモデルは、統計的ノイズの範囲内でFP32でトレーニングされたベースラインと一致することが多く、これは量子化が一種の正則化として機能し、微小な数値の詳細へのオーバーフィッティングを防いでいるためと考えられる。
FP8はさらに精度を下げ、重みと活性度を8ビットに圧縮する。つの標準エンコーディングが存在する:E4M3(4ビットの指数、3ビットの仮数)は前方パスの精度を優先し、E5M2(5ビットの指数、2ビットの仮数)は勾配の大きさが大きく変化する後方パスの範囲を優先する¹¹⁷ Ironwoodは両方のフォーマットに対してネイティブのFP8サポートを実装しているが、以前のTPUはソフトウェア変換によってFP8をエミュレートしていた¹¹⁸。
トレーニング時に量子化を意識することで、FP8の数値的な成功が可能になる。FP8でゼロから学習したモデルや、FP8を意識した手法で微調整したモデルは、フォーマットの限られた精度を許容する重み分布を学習します。トレーニング後の量子化(トレーニング後にFP32モデルをFP8に変換すること)は、慎重にキャリブレーションを行わないと品質が低下することが多い。
INT8の量子化により、さらに大きなメモリ節約と推論の高速化を実現。GoogleのAccurate Quantized Training (AQT)は、bfloat16ベースラインと比較して最小限の品質損失で、TPU上でのINT8学習を可能にします¹⁰ この技術は、量子化を意識した学習をゼロから適用し、学習後の近似ではなく、学習中にモデルがINT8の制約に適応することを可能にします。
混合精度戦略は戦略的にフォーマットを組み合わせる。前方パスは活性化と重みにFP8を使用し、後方パスは勾配にFP8 E5M2またはbfloat16を使用し、オプティマイザ状態は重みの更新時の数値的安定性のためにFP32のままである¹²¹混合アプローチは速度、メモリ、精度のバランスをとり、多くの場合、4倍高速に実行しながらFP32の90%以上の品質を達成する。
精度のトレードオフは、スピードやメモリだけでなく、数値的安定性の考慮にも及ぶ。バッチ正規化、レイヤー正規化、ソフトマックスでは、精度を下げた場合の数値処理に注意が必要です。softmaxの大きな指数は、FP8またはbfloat16の範囲をオーバーフローする可能性があります。指数化の前に最大対数を引くことで、数学的等価性を維持しながらオーバーフローを防ぐことができます。
プログラミングモデルと並列化戦略
SPMDと自動パーティショニング
Single Program, Multiple Data (SPMD)パラダイムは、プログラマーがTPU実行についてどのように考えるかを根本的に形作ります。複数のプロセスを調整するために明示的なメッセージパッシングコードを書くのではなく、開発者は単一のプログラムを書き、デバイス間でデータをどのように分割すべきかをアノテートします。
GSPMD (General SPMD)はXLAの自動パーティショニングロジックを実装している。このシステムは、テンソルのシャーディングアノテーションと計算グラフ構造を分析し、どのデバイスでどの操作が実行され、正しいセマンティクスを維持するためにどのような通信が必要かを決定する。¹²⁴ 自動化により、テンソル形状の不一致、不正な集団操作順序、不適切な同期によるデッドロックなど、手書きの分散コードでよく見られるバグのクラス全体を排除する。
コンパイラの制約伝播エンジンは、最小限のアノテーションからシャーディングの決定を推測します。GSPMDは、中間演算を通して制約を伝播し、効率的な分配を自動的に選択します。 ¹²2075 ⁵ ある演算に対して複数の有効なシャーディングが存在する場合、コンパイラは代替案の通信コストを推定し、最もコストの低いオプションを選択します。
高度な最適化は、通信と計算をオーバーラップさせます。レプリカ間で勾配を同期させるAll-reduceオペレーションは、最初のレイヤーの勾配が完了するとすぐに開始し、後続のレイヤーのバックワードパスと並行して実行することができます¹²⁶ コンパイラーは、オーバーラップを最大化するようにコレクティブを自動的にスケジューリングし、十分な通信時間を逐次実行に比べて2倍以上削減します。
再マテリアライゼーションは、計算とメモリを交換します。勾配計算のためにすべての前方パスの活性を保存するのではなく、コンパイラーは、メモリ圧力が閾値を超えたときに、後方パスの活性を選択的に再計算します。 ¹²⁷ このトレードオフは、計算がメモリ帯域幅を上回ることが多いTPUで特にうまく機能し、再計算がメモリトラフィックよりも安くなります。
データ並列、テンソル並列、パイプライン並列
データ並列化は、最も簡単な分散トレーニング戦略である:N台のデバイスに完全なモデルを複製し、各レプリカで異なるデータバッチを処理する。ローカルで勾配を計算した後、all-reduceによりレプリカ間で勾配を集約し、すべてのデバイスが同一の重み更新を適用する。 ¹²⁸ このアプローチは、通信時間が計算時間を支配するまで線形にスケールする。典型的には、イーサネットネットワーキングを使用するGPUは1,000台程度だが、ICIを使用するTPUは10,000台以上である。
テンソル並列処理(モデル並列処理とも呼ばれる)は,個々の処理をデバイス間で分割する.行列の乗算Y = W @ Xは、重み行列Wをデバイス間で分割し、各デバイスが出力の一部を計算します。
テンソル並列の通信パターンは,データ並列とは大きく異なる.テンソル並列では,各レイヤーの後にall-reduceを行うのではなく,完全なテンソルを必要とする操作の前にall-gatherを行い,分散計算の後にreduce-scatterを行う必要がある¹³¹ 通信量は,パラメータサイズではなく,モデルのアクティブ化サイズに比例するため,データ並列とは異なるボトルネックが発生する.
パイプライン並列は、デバイス間でシーケンシャルなモデル層を分割し、異なるステージで異なるマイクロバッチを同時に処理します。GPipeは、メモリ使用量を抑制しながらパイプラインの利用率を最大化するために、注意深くスケジューリングする戦略を導入しました。³²各デバイスは、1つのマイクロバッチのフォワードパスを処理し、アクティベーションを次のステージに送信し、次のマイクロバッチを処理します。
勾配の陳腐化はパイプラインの並列性を複雑にします。PipeDreamのような洗練されたスケジューリングアルゴリズムは、高いスループットを維持しながら、澱みを最小限に抑えることができます。
3次元並列は3つの戦略をすべて組み合わせたものです。データ並列は「データ」次元に、テンソル並列は「モデル」次元に、パイプライン並列は「パイプライン」次元に分散します。³⁴ モデルアーキテクチャ、ハードウェアトポロジー、および通信コストに基づいて次元のバランスを慎重にとることで、スループットを最大化します。GPT-3スケールのモデルでは、8~16レプリカにわたるデータ並列性、4~8GPUにわたるテンソル並列性、および4~16ステージにわたるパイプライン並列性を備えた3次元並列性が一般的に使用されます。
シャーディング戦略と最適化
シャーディング戦略を選択するには、数学演算とそのデータ依存関係を理解する必要がある。行列の乗算C = A @ Bは、複数の有効なシャーディングが可能である:AとBの両方を複製し、部分的な結果を計算する(計算前に通信)、Bを列方向にシャーディングし、結果を収集する(計算後に通信)、またはAを行方向に、Bを列方向にシャーディングし、通信は行わないが、デバイスごとの行列は小さくなる。
集合的な操作コストが最適な戦略を決定する。All-reduceのコストはテンソルサイズに対して線形にスケーリングされますが、ツリーベースやリングベースのリダクションアルゴリズムではデバイス数に対して非線形にスケーリングされます¹³⁶All-gatherとreduce-scatterは異なるスケーリング特性を示します。コンパイラはこれらのコストをモデル化し、総通信時間を最小化するシャーディング戦略を選択します。
大規模な言語モデルには、シーケンスの並列性が不可欠である。アテンションメカニズムは、キーバリューキャッシュがシーケンスの長さとバッチサイズに伴って増大するため、メモリボトルネックを引き起こす。シーケンスの次元に沿ってパーティショニングすることで、メモリ負担をデバイスに分散し、アテンション計算自体にのみ通信を導入します。
エキスパートの並列処理は、異なるエキスパートが異なるトークンを処理するMoE(Mixture-of-Experts)モデルを処理します。シャーディング戦略は、すべてのデバイスに共有レイヤーを複製しますが、エキスパートを分割し、各トークンを指定されたエキスパートデバイスにルーティングします。
オプティマイザの状態シャーディングは、大規模モデルのメモリ・オーバーヘッドを削減します。Adamのようなオプティマイザは、各パラメータに対して運動量と分散 の統計量を保存するため、必要なメモリはパラメータだけよりも3倍多くな ります。パラメーターを複製したまま、オプティマイザーの状態をデバイス間でシャー ディングすることで、固定されたメモリー予算内でより大規模なモデルのトレーニングが可能になります ¹³⁹ この戦略では、重みの計算中にオプティマイザーの状態の更新を収集する必要がありますが、デバイスごとのメモ リーフットプリントは大幅に削減されます。
パフォーマンス分析とベンチマーキング
MLPerf の結果と競合他社のポジショニング
MLPerfは、AIアクセラレータの性能を学習と推論のワークロードにわたって測定する業界標準のベンチマークを提供します。Googleは競争力のある性能を示すTPUの結果を定期的に提出しており、世代を超えた進化はアーキテクチャの明確な改善を示しています。
TPU v5eは、9つのMLPerfトレーニングカテゴリのうち8つでトップクラスの結果を達成¹⁴¹ この幅の広さは、大規模言語モデルだけでなく、コンピュータビジョン、推奨システム、科学計算ワークロード全体で競争力のあるパフォーマンスを発揮するアーキテクチャの汎用性を示しています。BERTトレーニングは、NVIDIA A100 GPUよりも2.8倍高速に完了し、トランスフォーマーに最適化されたアーキテクチャを検証しました。
2025年6月に発表されたMLPerf Training v5.0では、Llama 3.1 405Bベンチマークが導入され、スイート内で最大のモデルとなっています¹⁴³このベンチマークでは、マルチノードスケーリング、通信オーバーヘッド、メモリ容量が以前のテストよりも強調されています。Google CloudはTPUの提出で参加したが、詳細な性能比較は公式結果の発表まで保留されたままである。
MLPerf Inference v5.0には4つの新しいベンチマークが含まれている:Llama 3.1 405B、低レイテンシアプリケーション向けの Llama 2 70B、RGAT グラフニューラルネットワーク、3D オブジェクト検出用の PointPainting です。
推論ベンチマークでは、TPUのアーキテクチャの強みが特に評価されています。バッチ推論ワークロードは、MXUの大規模な並列性を活用し、トランスフォーマーサービングで競合アクセラレーターより4倍高いスループットを達成しています。¹⁴⁵ シングルクエリーのレイテンシーは、TPUの決定論的実行とサーマルスロットリングがないことから恩恵を受け、一部のGPUデプロイメントを悩ませるパフォーマンスのばらつきなしに、一貫したレイテンシーを実現します。
エネルギー効率指標は、TPUの優位性が世代を超えて拡大していることを示している。TPU v4はTPU v3よりワットあたり2.7倍優れた性能を示し、Trilliumはv5eより67%向上した。¹⁴⁶ Ironwoodは、絶対性能が大幅に高いにもかかわらず、Trilliumよりワットあたり2倍優れた性能を主張している。
実世界でのトレーニングと推論パフォーマンス
実運用ワークロードは、合成ベンチマークにはない性能特性を明らかにする。Googleは、実際の使用パターンとスケーリング要件におけるTPUの動作を実証する内部サービスの結果を公表している。
ResNet-50 ImageNetのトレーニングは、コンピュータビジョンのワークロード性能のベンチマークとして広く引用されているTPUポッド上で、28分で完了する¹⁴⁹Time-to-accuracyメトリックは、理論的なFLOPsだけでなく、データのロード、オーグメンテーション、分散勾配の同期、チェックポイントの保存を含む完全なトレーニングプロセスをキャプチャする。
T5-3B言語モデルのトレーニングが、トランスフォーマーアーキテクチャにおけるTPUの優位性を実証。TPUポッドでは30億パラメータモデルのトレーニングが12時間であるのに対し、同等のGPUコンフィギュレーションでは31時間である。
GPT-3スケールのワークロード(パラメータ数175B)では、TPUの方が最新のGPUよりも1.7倍高速な時間対精度を達成しています¹⁵¹ メモリ容量と帯域幅が重要な制約となる、さらに大規模なモデルでは性能差が広がります。Ironwoodの192GB HBM3eは、複雑なテンソル並列処理を必要とするモデルを低メモリで処理することを可能にします。
スケーリング効率の測定により、巨大なスケールまでほぼリニアに高速化することが実証された。Google Researchは、32,768TPUで特定の変換器トレーニングのワークロードに対して95%のスケーリング効率を報告した。
FLOPS利用率メトリクスは、ワークロードが利用可能なコンピ ューターをどれだけ効果的に活用しているかを明らかにします。Transformerモデルは通常、TPU上で90%のFLOPS利用率を達成します。これは、理論上のピーク性能の90%が実際の処理に変換されることを意味します¹⁵³高い利用率は、メモリボトルネックを排除するオペレーションフュージョン、大規模行列乗算におけるシストリックアレイの効率性、および無駄なサイクルを最小限に抑えるコンパイラの最適化に起因します。
プロダクション推論サービスは、1日あたり数十億のクエリで持続的なパフォーマンスを実証している。Google TranslateはTPUで毎日10億のリクエストを処理する。¹⁵⁴ YouTubeのレコメンデーションはTPUアクセラレーションモデルを使って20億のユーザーに提供する。
エネルギー効率と総所有コスト
消費電力は、データセンターの運用コストと環境の持続可能性に直接影響します。TPUの世代を超えたエネルギー効率の改善により、運用コストと二酸化炭素排出量の両方が大規模に削減されます。
TPU v4は、250WのTDP仕様にもかかわらず、実稼働負荷での平均消費電力はわずか200Wでした⁸⁸平均消費電力とピーク消費電力の間に余裕があるため、柔軟な熱設計とプロビジョニングが可能になります。GPUとは対照的に、持続的な作業負荷はしばしばTDPの限界に達し、保守的なラック電力バジェットが必要となります。
IronwoodのTDP 600Wは、前世代よりも絶対的な消費電力は高いものの、1ワットあたりの演算性能は飛躍的に向上しています⁵⁹ チップあたり4.6PFLOPSのFP8性能は、1ワットあたり約7.7TFLOPSとなり、同等のワークロードにおいて、最新のGPU効率と同等か、それを上回る性能を発揮します。
データセンターの電力使用効率(PUE)は、チップレベルの効率を増幅します。GoogleのTPUデータセンターのPUEは1.1であり、冷却、電力変換、ネットワークにかかるチップ消費以外の電力オーバーヘッドはわずか10%である。PUEが低いのは、先進的な冷却システム、効率的な電力供給、MLワークロードに最適化されたデータセンター設計によるものです。
カーボンインテンシティへの配慮は、電力だけでなくエネルギー源にも及んでいる。Googleは再生可能エネルギーの調達とカーボンオフセットプログラムを通じて、カーボンニュートラルな電力でTPUデータセンターを運営している。
総所有コスト(TCO)分析では、取得コスト、消費電力、冷却要件、メンテナンス費用を考慮する必要があります。TPUを導入した場合、GPUを導入した場合と比較してTCOが20-30%削減されるのが一般的ですが、これは主にワットあたりの性能が優れていることと、冷却の複雑さが軽減されたことが要因です¹⁶²。
冷却インフラのコストは、電力密度に応じて非線形に増加する。空冷ラックは通常、1ラックあたり15~20kWを上限とし、その後エキゾチックな冷却ソリューションが必要になります。高出力GPUはこの限界を超え、資本コストと運用コストが大幅に高い液冷インフラが必要になることもある。TPUの効率性により、より多くの導入が空冷の範囲内に収まり、データセンターの設計が簡素化されます。
技術的な利点:TPUが優れている点
ハードウェアによる集団演算の高速化
TPU ICIの特殊な集団演算サポートは、従来のネットワークアクセラレータと比較して最も大きな利点の1つを提供します。分散トレーニングで勾配を同期させるための主力演算であるAll-reduceは、TPU ICIではイーサネットベースのGPU実装と比較して10倍高速に実行されます。
パフォーマンスのギャップは、アーキテクチャの統合に起因する。アプリケーションコードがコレクティブライブラリ(NCCL、Horovodなど)を起動し、コレクティブライブラリがパケットを生成してネットワークスタックに渡し、ネットワークスタックがデータをNICに転送し、NICがワイヤにシリアライズし、スイッチを通過し、受信NICでデシリアライズし、プロセスを逆にします。各レイヤーはレイテンシーを追加し、メモリ階層を通してデータをコピーし、プロトコル処理のためにCPUサイクルを消費する。
TPU ICIは、ソフトウェアレイヤーを経由することなく、ハードウェアでコレクティブを実装する。操作はTensorCoreから直接開始され、専用のICIリンクを介してデータをストリーミングし、ホストCPUを介さずに完了します。直接的なハードウェアパスにより、従来の実装を支配していたオーバーヘッドがなくなります。
光回線スイッチトポロジーは最適な集合アルゴリズムを可能にします。リングベースのall-reduceはN個のデバイスに対して2(N-1)個のメッセージしか必要とせず、トーラスのトポロジーは最短経路ルーティングを提供し、待ち時間を最小化する。
統一されたメモリ空間と簡素化されたプログラミング
TPUの統一メモリモデルは、GPUの複雑なメモリ階層に比べてプログラミングを簡素化します。プログラマーは、ホストRAM、GPUグローバルメモリ、共有メモリ、レジスタファイル間の転送を管理するのではなく、単一のHBMプールについて推論します。単純化されたモデルはバグを減らし、開発速度を速めます。
メモリの断片化は懸念事項ではなくなりました。GPUは断片化されたヒープからメモリを割り当てますが、時間の経過とともに割り当てと解放が繰り返され、コンパクションを必要とする穴ができます。コンパイラの静的解析によるTPUのメモリ管理は、実行時の断片化を完全に回避します。
このプログラミングモデルは、CUDAエラーのクラス全体を排除します。不正なポインタ演算による「不正なメモリ・アクセス」や、CPUとGPU間のキャッシュ・コヒーレンシーのバグ、cudaDeviceSynchronize()呼び出しの欠落による同期化エラーがなくなります。より高度な抽象化により、CUDAプログラミングでよくあるフットガンを防ぐことができます。
決定論的実行と再現性
浮動小数点の非結合性は、並列計算における再現性の問題を引き起こします。(a+b)+cという式は、丸め誤差によってa+(b+c)とは異なる結果をもたらす可能性があり、並列削減はレース条件によって実行ごとに異なる順序で合計される可能性があります。
TPUの実行は、典型的なGPU実装よりも強力な決定性を示す。シストリックアレイの固定データフローパターンは、実行全体にわたって同一の演算順序を保証する。集合演算は、到着順序に基づく場当たり的な集約ではなく、決定論的な縮小ツリーに従う。この予測可能性により、同一のハイパーパラメータとデータがビット単位で同一のモデル重みを生成する再現可能なトレーニングが可能になる。
デバッグは決定論から多大な恩恵を受ける。非決定論的なトレーニングは、根本的な原因となる失敗をほぼ不可能にする。つまり、NaNは正真正銘のアルゴリズムのバグによるものなのか、それともランダムなレースコンディションによるものなのか?決定論的な実行は、失敗が確実に再現されることを意味し、体系的なデバッグアプローチを可能にする。
科学計算アプリケーションは、特に再現性を重視する。気候モデル、創薬シミュレーション、物理学研究では、異なる研究者が同一の結果を再現できるような検証可能な結果が求められます。TPUの決定論は、非決定論的な選択肢を競うよりも科学的手法をサポートします。
コンパイラの最適化と開発者の生産性
XLAの積極的な最適化により、手動でチューニングすることなく、"すぐに "大幅な性能向上が実現します。研究者の報告によると、イーガー実行フレームワークと比較して、コンパイルだけでモデルのスループットが40%向上しています。
フュージョン最適化は特に開発者にメリットがある。CUDAで手作業でオペレーションを融合するには、カスタムカーネルを書き、正しさをテストし、フレームワークのバージョンに渡ってコードを維持する必要があります。XLAは自動的に操作と更新を融合し、モデルの進化に合わせて融合戦略を適応させるので、メンテナンスの負担がなくなります。
レイアウト変換の自動化により、手作業による最適化を数週間節約できます。GPUに最適なテンソルレイアウトを決定するには、さまざまな配置をプロファイリングし、手動で転置を挿入し、メモリ割り当てパターンを慎重に管理する必要があります。XLAは自動的にレイアウトを試行し、最も高速なものを選択するため、開発者は低レベルのパフォーマンスエンジニアリングではなく、モデルアーキテクチャに集中することができます。
生産性の向上は、研究チームの生産性を向上させます。インフラの最適化にかかる時間を節約することで、科学的進歩が加速し、より多くの実験とより速い反復サイクルが可能になります。GPU CUDAプログラミングからTPU JAXベースのワークフローに移行した場合、開発速度が3倍向上したと報告されています。
技術的な限界と欠点
プラットフォームのロックインとオンプレミスの制約
TPUへのアクセスはGoogle Cloud Platformを通じてのみ利用可能であるため、オンプレミスでの導入ができず、ベンダーロックインの懸念がある。
AIが重要なインフラとなるにつれ、この制約はますます重要になっている。単一のクラウドプロバイダーに依存すると、事業継続のリスクが発生する。価格の変更、可用性の中断、サービスの停止により、コストのかかる移行を余儀なくされる可能性がある。
マルチクラウド戦略は摩擦に遭遇する。TPUを標準とする組織は、モデルを再トレーニングしたり、異なるアクセラレータアーキテクチャ用に別々のコードベースを維持したりすることなく、他のクラウドに簡単にバーストしたり、マルチクラウドの冗長性を実装したりすることができない。
CUDAエコシステムの成熟度格差
NVIDIAのCUDAプラットフォームは、TPUが及ばない15年以上のエコシステム開発、ライブラリ、ドキュメント、コミュニティの知識を蓄積している。
ライブラリの利用可能性は、圧倒的にCUDAに有利です。コンピュータグラフィックス、分子動力学、計算流体力学、ゲノミクスなどの専門領域では、過去数十年にわたって何千ものCUDA最適化ライブラリが蓄積されてきた。TPUに相当するものは存在しないことが多く、CPUフォールバック(パフォーマンスを破壊する)か、数ヶ月の移植作業が必要になる。
コミュニティのサポートは桁が違う。Stack Overflowには何十万ものCUDAに関する質問があり、詳細な回答が掲載されている。カンファレンスでの講演、学術論文、ブログ投稿は、主にCUDAプログラミングに焦点を当てている。TPUプログラマーは、比較的少ないリソース、長いデバッグサイクル、相談できる専門家の少なさに直面している。
教材やチュートリアルは、圧倒的にCUDAをターゲットにしている。大学のコースでは、CUDAを使用したGPUプログラミングを教えています。オンラインコースはCUDAに焦点を当てている。人材パイプラインは、TPUの専門家よりもCUDAの経験豊富なエンジニアをはるかに多く輩出しており、雇用とトレーニングに課題をもたらしている。
カスタム・カーネル開発は、エコシステムのギャップを例証している。最適化されたCUDAカーネルを書くことは、依然として自明ではないが、広範なドキュメント、プロファイリングツール、サンプルコードの恩恵を受けている。PallasはカスタムTPUカーネルを可能にするが、ツールはあまり成熟しておらず、知識ベースも少ない。学習曲線があるため、パフォーマンスが最も重要な最適化以外はお勧めできません。
ワークロードの専門化と柔軟性の制約
TPUのアーキテクチャは、特定の作業負荷パターンに最適化されています。主に、規則的なアクセスパターンと大きなバッチサイズを持つ高密度行列乗算です。スイートスポット以外の演算では、性能の崖が発生する。
動的な形状はTPU実行モデルに挑戦する。XLAコンパイラは、最適化とコード生成のために固定テンソル次元を仮定している。可変のシーケンス長、動的な制御フロー、データに依存する形状を持つモデルは、最大サイズへのパディング(計算量とメモリの浪費)、または異なる形状ごとに再コンパイル(性能の破壊)が必要です ¹⁸⁸。
スパースコアにもかかわらず、スパース演算のサポートは限られている。スパース行列-行列乗算は、科学計算やグラフ・ニューラル・ネットワークで一般的な作業負荷ですが、MXUやVPUでは効率的な実装がありません。特化されたSparseCoreは埋め込みテーブルを処理しますが、一般的なスパース線形代数は処理しません。
小バッチの推論はTPUの並列リソースを十分に活用できていない。256×256のシストリック配列は、グリッドを生産的な作業で満たす大きな行列で繁栄する。シングルクエリ推論では、ほとんどのMACがアイドル状態になり、クエリあたりのレイテンシとコストは、低バッチシナリオ用に最適化されたGPUの代替よりも悪化します。
不規則な計算パターンはシストリックアレイの効率を低下させる。予測不可能な分岐、再帰的構造、ポインタを追いかけるメモリアクセスを持つアルゴリズムは、TPUのパフォーマンスが低い。
非MLワークロードがTPUアクセラレーションの恩恵を受けることはほとんどない。科学シミュレーション、ビデオエンコーディング、ブロックチェーン検証、レンダリングはすべて、TPUの方が行列演算のピークFLOPが高いにもかかわらず、GPUのより一般的なアーキテクチャで高速に実行される。
デバッグと開発ツールのギャップ
NVIDIAのエコシステムには、成熟したプロファイリングツール(Nsight Systems、Nsight Compute、nvprof)、デバッガ(cuda-gdb)、および数十年にわたって洗練されてきた解析フレームワークが含まれています。TPUツールは存在しますが、洗練度ではかなり遅れています。
XProfは、TensorBoardの統合を通じて基本的なプロファイリングを提供しますが、NVIDIAツールが公開するきめ細かなハードウェアカウンタアクセスを欠いています。キャッシュ・ミス・レート、占有率、ワープ・ダイバージェンス、メモリバンクの競合など、GPU最適化の重要なメトリクスはすべて、アーキテクチャが根本的に異なるため、TPUに相当するものがありません。
エラーメッセージはしばしば根本的な原因を不明瞭にする。XLAのコンパイルに失敗すると、シェイプのミスマッチやサポートされていない操作に関する不可解なメッセージが表示され、解決に関する明確なガイダンスがありません。CUDAのエラーは、役に立たないことで悪名高いが、15年にわたるStackOverflowの説明と部族的知識から恩恵を受けている。
マルチチップポッド上の分散トレーニングのデバッグは、特別なツールなしでは不可能に近い。レース状態、勾配同期バグ、集団操作の失敗は、非決定論的なエラーとして現れ(皮肉なことに、TPUは決定論的な利点があるにもかかわらず)、再現性に一貫性がなく、体系的な診断が困難です。
反復ループは、複雑なモデルには苦痛を伴う。形状の変更やアーキテクチャの変更に伴う再コンパイルには数分を要し、コンパイラが動作している間、開発が止まってしまいます。CUDAのイーガー実行モデルは、ピーク性能が低いにもかかわらず、より高速な反復を可能にします。
実世界での展開プロダクション・アット・スケール
アントロピック・クロード:マルチプラットフォーム戦略
Anthropicが2025年10月に発表した100万個以上のTPUチップの導入は、史上最大規模のAIアクセラレーターの公約を意味する¹⁹⁸ 同社は、2026年にオンラインになるギガワット以上の計算能力を、将来のクロードモデルのトレーニングとサービス専用に利用する計画だ。
その規模は、これまでの展開を桁違いで凌駕する。Ironwood TPUとして構成された100万個のチップは、約4.6エクサフロップスのFP8計算を実現し、これはわずか5年前のTop500スーパーコンピュータリスト全体の40倍以上の性能である。
Anthropicは、GoogleのTPU、AmazonのTrainium、NVIDIAのGPUにまたがる意図的なマルチプラットフォームのハードウェア戦略を追求しています。クロードは、3つのプラットフォームすべてにまたがるデプロイメントからグローバルにサービスを提供しており、リクエストのルーティングは、容量の可用性と地域のレイテンシ要件に基づいています。
2025年8月に同社が行った技術的な事後調査により、規模が拡大するにつれて展開の複雑さが明らかになった。クロードAPI TPUサーバーの設定ミスがトークン生成エラーを引き起こし、英語プロンプトのタイ語や中国語の文字に予期せぬ高い確率が割り当てられることがあった。
XLA: TPU コンパイラの潜在的なバグが、Claude Haiku 3.5 に影響する別のデプロイメントで発見されました。このバグは、特定のモデル・アーキテクチャとコンパイラ・フラグの組み合わせが不具合を露呈するまで、何ヶ月も発見されずに存在していた。
Anthropicのエンジニアは、TPUの価格性能と効率を主な選択基準として挙げました。より大きなモデルのトレーニング、より多くのハイパーパラメータ設定の探索、より速い反復はすべて、FLOPあたりのコストを削減することに起因しています。
グーグル ジェミニ:当初からTPU向けに設計
GoogleのGeminiモデルは、最初からTPUの特性に合わせてアーキテクチャと学習手順が設計されており、TPUのみで学習と処理を行う。
Geminiのデプロイメントでは、最も重要なモデルバリアントのトレーニングとサービス用に、50,000個のTPU v6eチップを使用していると報告されている⁵⁵ 巨大なポッドスケールには、洗練されたオーケストレーション-何千ものチップにまたがるジョブのスケジューリング、ボトルネックを防ぐためのチェックポイント調整、失われた作業を最小限に抑えるための障害回復、障害が伝播する前に劣化したノードを特定するためのリアルタイムモニタリング-が必要だ。
Googleは、Gemini 2.0をTrillium TPUでトレーニングし、フロンティアモデル開発のための第6世代アーキテクチャを検証しました。
TPUの推論最適化を活用したモデル提供インフラ。バッチ処理は複数のユーザーリクエストを集約し、MXUの利用率を最大化する。キー・バリュー・キャッシュ管理はHBMの容量を活用し、ディスクスワップなしで長期間のコンテキスト処理を可能にします。このアーキテクチャは、大量のグローバルリクエストを処理しながら、複雑なクエリに対して秒以下の応答時間を実現します。
生産監視システムは、50,000以上のTPUを継続的に追跡し、モデルの品質や可用性を低下させる可能性のある異常を検出します⁰⁸テレメトリーは、すべてのチップのエラー率、レイテンシのパーセンタイル、スループット、メモリ圧力、熱特性をキャプチャします。機械学習モデルはテレメトリ・ストリーム自体を分析し、故障が発生する前に故障を予測し、先制的なメンテナンスをトリガーします。
追加のプロダクション・デプロイメント
MidjourneyはGPUからTPUインフラに移行し、画像生成ワークロードで65%のコスト削減と40%のレイテンシ改善を達成しました。
TPU上のCohereの言語モデルは、以前のGPUデプロイメントと比較して3倍のスループットを達成しました。同社はJAXのSPMD機能を活用し、TPUポッド間でモデルを効率的に並列化した。
スナップは、拡張現実機能、推奨システム、クリエイティブなAIツールをサポートする10,000個のTPU v6eチップの容量を確保した²¹¹ この導入は複数の地域にまたがり、地域間でモデルの一貫性を維持しながら、スナップチャットのグローバルユーザーベースに低遅延を保証する。
学術機関が研究にTPUを採用するケースが増えている。TPUリサーチクラウド(TRC)プログラムは、研究者にTPUへの無料アクセスを提供し、以前は資金力のある企業ラボのみがアクセス可能だった規模での実験を可能にする。
デバッグ、プロファイリング、パフォーマンスの最適化
XProfとTensorBoardの統合
XProfは、TPUワークロードの主要なプロファイリングツールを形成し、CPU、GPU、TPUにまたがるJAX、PyTorch/XLA、TensorFlowプログラムのパフォーマンス分析を提供します。
インストールにはTensorBoardプラグインが必要: pip install tensorboard_plugin_profile tensorboard.TPU VMでプロファイリングを実行するには、トレーニングや推論中のトレースをキャプチャし、結果をTensorBoardにアップロードし、ボトルネックを特定するために可視化を分析する。
概要ページでは、ステップ時間の内訳、デバイス使用率、トップレベルのボトルネックの特定を含む、ハイレベルのパフォーマンスサマリーメトリクスを提供します。
トレース・ビューワとタイムライン解析
トレースビューワーは、オペレーションがいつ実行され、データ転送がいつ行われ、アイドル時間がどこで蓄積されたかを、詳細なタイムラインで表示します。
トレースを理解するには、共通のパターンを認識する必要がある。操作間のギャップが長い場合は、コンパイルのオーバーヘッド、データロードのボトルネック、最適化されていないデータパイプラインによるPythonのオーバーヘッドを示す。繰り返される小さな操作は、融合が不十分であることを示唆する。ミリ秒に及ぶ集団操作は、通信の非効率性やシャーディング戦略の不備を示唆する。
色分けは、緑が計算、青がメモリ転送、オレンジが通信、赤がアイドル時間です。最適化されたワークロードは、色のついたブロックが密集し、赤色のギャップが最小限に抑えられている。最適化されていないコードでは、タイムラインがまばらになり、長い赤色のストレッチはリソースの浪費を示す²¹⁸。
PyTorch/XLA は、トレースに表示されるコードに挿入されるユーザー注釈をサポートしています。PyTorch/XLA は、トレースに表示されるコードに挿入されるユーザーアノテーションをサポートしており、パフォーマンスの振る舞いを特定のモデルコンポーネントにマッピングすることができます。
メモリプロファイルツールとOOMデバッグ
メモリ不足(OOM)エラーは大規模モデル開発を悩ませます。メモリ・プロファイル・ツールは、実行中のデバイス・メモリ使用量を監視し、OOM エラーにつながるピーク使用量と割り当てパターンをキャプチャします。
このツールはメモリ消費量を経時的に可視化し、どのテンソールが最も容量を消費しているか、またいつ使用量がピークに達するかを表示します。この可視化によって、予想以上に大きな勾配バッファ、チェックポイントすべき活性化メモリ、XLAが除去できなかった一時テンソルなど、意外な割り当てが明らかになることが多い²²¹。
デバッグ戦略では、複数の手法によってメモリフットプリントを繰り返し削減する。勾配チェックポインティングは、後方パス中にアクティベーションを保存するのではなく、再計算する。オプティマイザの状態シャーディングは、アダムの運動量と分散をデバイス間で分散させる。混合精度により、FP32に比べてメモリを2倍削減。マイクロバッチ処理により、1つの大きなバッチではなく、より小さなバッチを順次処理。
高度なメモリ最適化には、コンパイラの決定を理解する必要がある。xla_dump_toフラグは、XLAが計算グラフをどのように変換したかを示す中間表現をエクスポートします。IRを分析することで、融合が成功したかどうか、不必要なコピーがどこで発生するか、どの操作が予想以上にメモリを割り当てるかが明らかになります²²³。
インプット・パイプライン・アナライザー
CPUの前処理はTPUトレーニングのボトルネックになることが多い。Input Pipeline Analyzerは、データのロードがアクセラレータの消費に追いついているか、TPUがバッチ待ちでアイドル状態になっているかを特定する。
このツールは、ホスト側の分析(CPUの前処理、データ増強、バッチアセンブリ)とデバイス側の実行(実際のTPU計算)を分離する。入力バウンドのワークロードでは、データのロード中にデバイスの利用率が低下する一方で、CPUの利用率はピークに達します。計算バウンドのワークロードは、CPUが快適にペースを維持しながら、高いデバイス利用率を維持します。
最適化戦略はボトルネックの場所に依存する。遅いホストの前処理は、より多くのCPUコアにデータロードを並列化する、サンプルごとのオーグメンテーションの複雑さを減らす、または消費に先駆けてバッチをプリフェッチするなどのメリットがあります。デバイス側のボトルネックには、データパイプラインのチューニングよりも、モデルアーキテクチャの変更、より良いフュージョン、シャーディングの調整が必要です。
テンソル処理ユニットの未来
グーグルの7世代にわたるアーキテクチャの進化は、特殊なAIアクセラレータにおける継続的なイノベーションを示している。IronwoodのFP8サポート、大容量メモリ、9,216チップのスーパーポッドスケーリングは、将来の発展の軌道を示唆している。
特定の演算については、FP4 またはそれ以下に向かって精度の低下が続くと思われる。新たな研究では、多くのニューラルネットワーク演算は、慎重なトレーニング手順により、極端な量子化を許容することが実証されている。将来のTPUは、FP4フォワードパス、FP8バックワードパス、FP32オプティマイザアップデートによる混合精度システムを実装するかもしれない。
メモリ容量はモデルサイズの増大と競合する。現在のフロンティアモデルはすでにアクセラレータメモリに負担をかけており、高度な並列化戦略を必要としている。次世代のTPUは、3D XPointや抵抗性RAMのような不揮発性メモリ技術を統合し、DRAMの消費電力を使わずにテラバイト規模のオンパッケージメモリを実現するかもしれません。
光インターコネクトは、回路スイッチングにとどまらず、光コンピューティング素子をも含む可能性がある。研究では、最小限の電力で光速で実行されるフォトニック行列乗算を探求しており、特定の演算のために光コプロセッサで電子シストリックアレイを補強する可能性がある。
スパース性のサポートは、エンベッディングだけでなく、一般的なスパース線形代数にまで拡大する可能性が高い。ニューラルネットワークの刈り込み技術は、90%以上の重みを品質を損なうことなくゼロにできることを示しています。将来のアーキテクチャは、ゼロ値計算を明示的に計算して破棄するのではなく、ネイティブにスキップするかもしれない³²¹。
TPUの成功の根底にあるアーキテクチャ原則(ドメインの特化、カスタム相互接続、共同設計ソフトウェアスタック、ビルディング規模のオーケストレーション)は、ますます特化されたアクセラレータの未来を指し示している。画一的なプロセッサーではなく、学習と推論、畳み込みネットワークとトランスフォーマー、高密度モデルと疎なモデル、短いシーケンスと長いシーケンスに最適化されたアクセラレーターが登場するかもしれません。
現在AIインフラを構築しているエンジニアは、TPUアーキテクチャを深く理解する必要がある。Google Cloudにデプロイするにしても、アクセラレータ市場でGoogleと競合するにしても、次世代のMLシステムを設計するにしても、TPUに具現化されている設計原理とトレードオフは、AIワークロードがハードウェアに求めるものについての基本的な真実を明らかにしている。シストリックアレイの数学、メモリ階層の設計、インターコネクトのトポロジー、コンパイラの最適化戦略は、TPUそのものをはるかに超えて適用可能な、数十年にわたる知恵の蓄積を表している。
TPU対GPUを定義する特殊性と汎用性の間の緊張は、いつまでも続くだろう。TPUは柔軟性を犠牲にして、狭いワークロードでの効率を極限まで高めている。GPUは、より幅広い適用性のために、ピーク時の効率を犠牲にします。最適な選択は、ワークロードの特性、規模、コスト制約、運用要件に完全に依存する。AIを大規模に成功させる組織は、単一のプラットフォームに標準化するのではなく、ワークロードの需要にアクセラレータ・アーキテクチャを適合させる異種混在戦略を採用することが増えています。
AnthropicのTPUへの100万チップのコミットメントは、アーキテクチャが最高スケールで生産成熟を達成したことを示している。2026年にオンラインになるマルチギガワットの配備は、AIが達成できる限界を押し広げるモデルを訓練するものであり、これらのモデルを可能にするインフラは、それに匹敵する組織はほとんどないほど洗練されたエンジニアリングを体現している。シストリック・アレイの65,536のマルチ演算ユニットがどのように連携してフロンティア・モデルを訓練するのかを理解することは、AIの将来を真剣に考える者にとって重要なことだ。
参考文献
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," October 23, 2025、 https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," November 7, 2025、 https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
Norman P. Jouppi 他, "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings,"Proceedings of the 50th Annual International Symposium on Computer Architecture(2023), arXiv:2304.01433.
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, October 2025、 https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," April 2017、 https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
Norman P. Jouppiら, "In-Datacenter Performance Analysis of a Tensor Processing Unit,"Proceedings of 44th Annual International Symposium on Computer Architecture(2017), arXiv:1704.04760.
Jouppiら、"In-Datacenter Performance Analysis"。
Jouppiら、"In-Datacenter Performance Analysis"。
ジョナサン・ホイ「AIチップ:Google TPU," Medium, accessed December 2025、 https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
ウィキペディア、「Bfloat16 浮動小数点フォーマット」、2025 年 12 月アクセス、 https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
Henry Ko, "TPU Deep Dive," personal blog, accessed December 2025、 https://henryhmko.github.io/posts/tpu/tpu.html.
Wikipedia, "Tensor Processing Unit", accessed December 2025、 https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
ウィキペディア「テンソル処理ユニット」。
ウィキペディア「テンソル処理ユニット」。
コウ、"TPUディープ・ダイブ"。
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM),", accessed December 2025、 https://openxla.org/xla/sparsecore.
JAX Scaling Guide, "How to Think About TPUs", accessed December 2025、 https://jax-ml.github.io/scaling-book/tpus/.
JAXスケーリングガイド、"TPUについてどう考えるか"。
コウ、"TPUディープ・ダイブ"。
JAXスケーリングガイド、"TPUについてどう考えるか"。
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," May 2024、 https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
Google Cloud Blog, "Introducing Trillium".
Google Cloud Blog, "Introducing Trillium".
Google Cloud Blog, "Introducing Trillium".
Google Cloud Blog, "Introducing Trillium".
Google Blog, "Ironwood:推論の時代のための最初のGoogle TPU」、2025年11月、 https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
XPU.pub「グーグルがアイアンウッドTPUにFP8を追加、ブラックウェルに勝てるか?2025年4月16日、 https://xpu.pub/2025/04/16/google-ironwood/.
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," April 10, 2025、 https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
コウ、"TPUディープ・ダイブ"。
XPU.pub、「グーグルがアイアンウッドTPUにFP8を追加」。
グーグル・クラウド・プレス・コーナー、"Anthropic to Expand Use"。
Telesens「Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture」2018年7月30日、 https://telesens.co/2018/07/30/systolic-architectures/.
テレセン「行列の掛け算を理解する」。
Jouppiら、"In-Datacenter Performance Analysis"。
テレセン「行列の掛け算を理解する」。
CP Lu, "Should We All Embrace Systolic Arrays?"Medium、2025年12月アクセス、 https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
Google Cloud Documentation, "TPU architecture", accessed December 2025、 https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
Google Cloud Documentation, "TPU architecture".
ホイ「AIチップ:グーグルTPU"
Telnyx, "Architecture insights:MXU と TPU コンポーネント」、2025 年 12 月アクセス、 https://telnyx.com/learn-ai/mxu-tpu.
コウ、"TPUディープ・ダイブ"。
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
SemiEngineering, "Tensor Processing Unit (TPU)", accessed December 2025、 https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
SemiEngineering, "Tensor Processing Unit (TPU)".
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
Google Cloud Documentation, "Cloud TPU performance guide", accessed December 2025、 https://cloud.google.com/tpu/docs/performance-guide.
OpenXLAプロジェクト、"SparseCoreを深く掘り下げる"
OpenXLAプロジェクト、"SparseCoreを深く掘り下げる"
OpenXLAプロジェクト、"SparseCoreを深く掘り下げる"
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
OpenXLAプロジェクト、"SparseCoreを深く掘り下げる"
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
OpenXLAプロジェクト、"SparseCoreを深く掘り下げる"
JAXスケーリングガイド、"TPUについてどう考えるか"。
JAXスケーリングガイド、"TPUについてどう考えるか"。
JAXスケーリングガイド、"TPUについてどう考えるか"。
コウ、"TPUディープ・ダイブ"。
JAXスケーリングガイド、"TPUについてどう考えるか"。
JAXスケーリングガイド、"TPUについてどう考えるか"。
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
コウ、"TPUディープ・ダイブ"。
Anthropic、"Google Cloud TPUの利用拡大"。
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
コウ、"TPUディープ・ダイブ"。
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
Leon Poutievski, "Mission Apollo:データセンター規模での光回線スイッチングの着地」、LinkedIn、2022年6月、 https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
コウ、"TPUディープ・ダイブ"。
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
Jouppi et al, "TPU v4: An Optically Reconfigurable Supercomputer".
JAXスケーリングガイド、"TPUについてどう考えるか"。
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning", accessed December 2025、 https://openxla.org/xla.
Daniel Snider and Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," academic paper, accessed December 2025、 https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
Snider and Liang, "Operator Fusion in XLA".
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)", accessed December 2025、 https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
OpenXLAプロジェクト、"XLA"。
PyTorch Documentation, "Pytorch/XLA Overview", accessed December 2025、 https://docs.pytorch.org/xla/master/learn/xla-overview.html.
OpenXLAプロジェクト、"SparseCoreを深く掘り下げる"
Mangpo Phothilimthana 他, "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers,"PACT 2021, accessed December 2025、 https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
JAX Documentation, "Introduction to parallel programming", accessed December 2025、 https://docs.jax.dev/en/latest/sharded-computation.html.
GitHub, "jax-ml/jax:Composable transformations of Python+NumPy programs", accessed December 2025、 https://github.com/jax-ml/jax.
OpenXLA Project, "Shardy Guide for JAX Users,", accessed December 2025、 https://openxla.org/shardy/getting_started_jax.
JAXドキュメント、"並列プログラミング入門"。
OpenXLA Project, "Shardy Guide for JAX Users".
OpenXLA Project, "Shardy Guide for JAX Users".
JAXドキュメント、"並列プログラミング入門"。
OpenXLA Project, "Shardy Guide for JAX Users".
PyTorch Documentation, "Pytorch/XLA Overview".
GitHub, "RFC: Evolving PyTorch/XLA for more native experience on TPU," Issue #9684, accessed December 2025、 https://github.com/pytorch/xla/issues/9684.
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode'," accessed December 2025、 https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
PyTorch Documentation, "Pytorch/XLA Overview".
PyTorch Documentation, "Custom Kernels via Pallas", accessed December 2025、 https://docs.pytorch.org/xla/master/features/pallas.html.
PyTorch Documentation, "Custom Kernels via Pallas".
PyTorch Documentation, "Custom Kernels via Pallas".
vLLM Blog, "vLLM TPU:TPU で PyTorch と JAX をサポートする新しい統合バックエンド", October 16, 2025、 https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
GitHub, "pytorch/xla", accessed December 2025、 https://github.com/pytorch/xla.
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, accessed December 2025、 https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
ウィキペディア、"Bfloat16浮動小数点フォーマット"。
ウィキペディア、"Bfloat16浮動小数点フォーマット"。
Paulius Micikeviciusら, "FP8 Formats for Deep Learning," arXiv:2209.05433, September 2022.
XPU.pub、「グーグルがアイアンウッドTPUにFP8を追加」。
Micikeviciusら、"ディープラーニングのためのFP8フォーマット"。
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e", accessed December 2025、 https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
StackGpu、「FP8、BF16、INT8」。
Jeffrey Tse, "Understanding FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats", personal blog, December 9, 2024、 https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization,", accessed December 2025、 https://pytorch.org/blog/pytorch-xla-spmd/.
OpenXLA Project, "Shardy Guide for JAX Users".
JAXドキュメント、"並列プログラミング入門"。
OpenXLA Project, "Shardy Guide for JAX Users".
コウ、"TPUディープ・ダイブ"。
JAXドキュメント、"並列プログラミング入門"。
Anthropic、"Google Cloud TPUの利用拡大"。
JAXドキュメント、"並列プログラミング入門"。
JAXドキュメント、"並列プログラミング入門"。
Adam Roberts 他, "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, March 2022.
ロバーツら、"モデルとデータのスケールアップ"。
JAXドキュメント、"並列プログラミング入門"。
JAXドキュメント、"並列プログラミング入門"。
OpenXLA Project, "Shardy Guide for JAX Users".
ロバーツら、"モデルとデータのスケールアップ"。
ロバーツら、"モデルとデータのスケールアップ"。
コウ、"TPUディープ・ダイブ"。
MLCommons, "Benchmark MLPerf Training", accessed December 2025、 https://mlcommons.org/benchmarks/training/.
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," June 2025、 https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," April 2025、 https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
コウ、"TPUディープ・ダイブ"。
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," accessed December 2025、 https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
Google Cloud Blog, "TPUの性能を数値化する".
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation", accessed December 2025、 https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
ウィキペディア「テンソル処理ユニット」。
XPU.pub、「グーグルがアイアンウッドTPUにFP8を追加」。
コウ、"TPUディープ・ダイブ"。
Google Cloud Blog、"TPU v4はパフォーマンス、エネルギー、CO2e効率の向上を可能にする"
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, accessed December 2025、 https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
バイトブリッジ、「GPUとTPUの比較分析レポート」。
Anthropic、"Google Cloud TPUの利用拡大"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
DataCamp, "Understanding TPU vs GPUs in AI: A Comprehensive Guide", accessed December 2025、 https://www.datacamp.com/blog/tpu-vs-gpu-ai.
コウ、"TPUディープ・ダイブ"。
DataCamp、"AIにおけるTPUとGPUを理解する"
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of ZOO," Medium, accessed December 2025、 https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
Snider and Liang, "Operator Fusion in XLA".
APXML, "Memory-Aware Data Layout Transformations".
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU,", accessed December 2025、 https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
CloudOptimo、「TPU vs GPU:2025年には何が違うのか?" 2025年12月アクセス、 https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
Phoenix NAP, "TPU vs. GPU:Differences Explained", accessed December 2025、 https://phoenixnap.com/kb/tpu-vs-gpu.
CloudOptimo, "TPU vs GPU".
DataCamp、"AIにおけるTPUとGPUを理解する"
Tailscale「TPU vs GPU:2025年のAIインフラはどちらが優れているか」2025年12月アクセス、 https://tailscale.com/learn/what-is-tpu-vs-gpu.
DataCamp、"AIにおけるTPUとGPUを理解する"
DataCamp、"AIにおけるTPUとGPUを理解する"
PyTorch Documentation, "Custom Kernels via Pallas".
フェニックスNAP「TPU vs. GPU:違いを説明"
コウ、"TPUディープ・ダイブ"。
OpenMetal, "TPU vs GPU:Pros and Cons", accessed December 2025、 https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
OpenMetal「TPU vs GPU:長所と短所"
フェニックスNAP「TPU vs. GPU:違いを説明"
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU,", accessed December 2025、 https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
DataCamp、"AIにおけるTPUとGPUを理解する"
Google Cloud Documentation, "Profile your model on Cloud TPU VMs,", accessed December 2025、 https://cloud.google.com/tpu/docs/cloud-tpu-tools.
DataCamp、"AIにおけるTPUとGPUを理解する"
コウ、"TPUディープ・ダイブ"。
GitHub, "RFC: Evolving PyTorch/XLA".
グーグル・クラウド・プレス・コーナー、"Anthropic to Expand Use"。
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner,", accessed December 2025、 https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
Anthropic、「最近の3つの問題の事後分析」、エンジニアリング・ブログ、2025年8月、 https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
人間主義、"最近の3つの問題の事後分析"
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure,", accessed December 2025、 https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," November 2025、 https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
コウ、"TPUディープ・ダイブ"。
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
Google Cloud, "Tensor Processing Units (TPUs)", accessed December 2025、 https://cloud.google.com/tpu.
TensorFlow Documentation, "Optimize TensorFlow performance using Profiler", accessed December 2025、 https://www.tensorflow.org/guide/profiler.
Google Cloud Documentation, "Profile your model on Cloud TPU VMs".
TensorFlow Documentation, "TensorFlow Profiler:Profile model performance", accessed December 2025、 https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
Google Cloud Documentation, "Profile your model on Cloud TPU VMs".
Google Cloud Blog, "PyTorch/XLA: Cloud TPU VMでのパフォーマンスデバッグ:Part III", accessed December 2025、 https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III".
Google Cloud Documentation, "Profile PyTorch XLA workloads", accessed December 2025、 https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
TensorFlowドキュメント、"Profilerを使用したTensorFlowパフォーマンスの最適化"
TensorFlowドキュメント、"Profilerを使用したTensorFlowパフォーマンスの最適化"
コウ、"TPUディープ・ダイブ"。
Google Cloud Documentation, "Cloud TPU performance guide".
TensorFlowドキュメント、"Profilerを使用したTensorFlowパフォーマンスの最適化"
TensorFlowドキュメント、"Profilerを使用したTensorFlowパフォーマンスの最適化"
TensorFlowドキュメント、"Profilerを使用したTensorFlowパフォーマンスの最適化"
TrendForce, "Google Unveils 7th-Gen TPU Ironwood".
Tse, "Understanding FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats".
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。
コウ、"TPUディープ・ダイブ"。